







Reference
UCB CS294 2017Fall Lecture11
CS294 Note
Optimal Control as a Model of Human Behavior
通常情况下,我们认为一个策略是最优的是最大化一个过程中的整体回报,在每一步之间相互独立的情况下,对于每一步来说的最优策略就是最大化该步的回报期望。写成数学表达式就是:
\mathbf { a } _ { 1 } , \ldots , \mathbf { a } _ { T } = \arg \max _ { \mathbf { a } _ { 1 } , \ldots , \mathbf { a } _ { T } } \sum _ { t = 1 } ^ { T } r \left( \mathbf { s } _ { t } , \mathbf { a } _ { t } \right)
\mathbf { s } _ { t + 1 } = f \left( \mathbf { s } _ { t } , \mathbf { a } _ { t } \right)
\pi = \arg \max _ { \pi } E _ { \mathbf { s } _ { t + 1 } \sim p \left( \mathbf { s } _ { t + 1 } | \mathbf { s } _ { t } , \mathbf { a } _ { t } \right) , \mathbf { a } _ { t } \sim \pi \left( \mathbf { a } _ { t } | \mathbf { s } _ { t } \right) } \left[ r \left( \mathbf { s } _ { t } , \mathbf { a } _ { t } \right) \right]
\mathbf { a } _ { t } \sim \pi \left( \mathbf { a } _ { t } | \mathbf { s } _ { t } \right)
但是数据肯定有随机性的,比如人类想拿一个水杯,伸手动作肯定不是直线的,但是走一些曲线最终却能拿到水杯,这也是 still most likely.
因此上面的最大 Reward 的模型肯定是没法用的了,对此提出用概率图的形式:
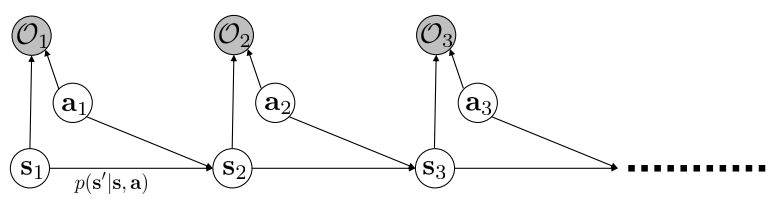
对于这个图的理解分为两部分:
- 忽略 O,这个图就是由 s,a -> s_
- 但是这样会缺少用来 Optimal 的表达式,因此引入 O,O 表示 s, a 有多大概率是趋向于达到最终目的,比如拿水杯的时候(O 二值化),当前 s,a 趋向于拿到水杯(O = 1),当前 s,a 趋向于不拿水杯(O = 0), 这样就可以忽略最优化中间过程,改为最优化目标。
因此改为最优化:
p ( \tau | \mathcal { O } _ { 1 : T } ) \tau is True
其中 O 可以数学表示为:
p \left( \mathcal { O } _ { t } | \mathbf { s } _ { t } , \mathbf { a } _ { t } \right) \propto \exp \left( r \left( \mathbf { s } _ { t } , \mathbf { a } _ { t } \right) \right)
因此:
p ( \tau | \mathcal { O } _ { 1 : T } ) = \frac { p \left( \tau , \mathcal { O } _ { 1 : T } \right) } { p \left( \mathcal { O } _ { 1 : T } \right) } \propto p ( \tau ) \prod _ { t } \exp \left( r \left( \mathbf { s } _ { t } , \mathbf { a } _ { t } \right) \right) = p ( \tau ) \exp \left( \sum _ { t } r \left( \mathbf { s } _ { t } , \mathbf { a } _ { t } \right) \right)
Inference
Backward message
首先我们想求取对每一个 s,a 的估值(类似 Q值)
\begin{aligned} \beta _ { t } \left( \mathbf { s } _ { t } , \mathbf { a } _ { t } \right) & = p \left( \mathcal { O } _ { t : T } | \mathbf { s } _ { t } , \mathbf { a } _ { t } \right) \\ & = \int p \left( \mathcal { O } _ { t : T } , \mathbf { s } _ { t + 1 } | \mathbf { s } _ { t } , \mathbf { a } _ { t } \right) d \mathbf { s } _ { t + 1 } \\ & = \int p \left( \mathcal { O } _ { t + 1 : T } | \mathbf { s } _ { t + 1 } \right) p \left( \mathbf { s } _ { t + 1 } | \mathbf { s } _ { t } , \mathbf { a } _ { t } \right) p \left( \mathcal { O } _ { t } | \mathbf { s } _ { t } , \mathbf { a } _ { t } \right) d \mathbf { s } _ { t + 1 } \end{aligned}
(本来想说这里缺个 a_,后面补上了)
p \left( \mathcal { O } _ { t + 1 : T } | \mathbf { s } _ { t + 1 } \right) = \int p \left( \mathcal { O } _ { t + 1 : T } | \mathbf { s } _ { t + 1 } , \mathbf { a } _ { t + 1 } \right) p \left( \mathbf{a}_{t+1} | \mathbf{s}_{t+1} \right) d \mathbf{a}_{t+1}
其中:
p \left( \mathcal { O } _ { t + 1 : T } | \mathbf { s } _ { t + 1 } , \mathbf { a } _ { t + 1 } \right) = \beta _ { t } \left( \mathbf { s } _ { t + 1 } , \mathbf { a } _ { t + 1 } \right)
因此在认为 actions are likely a priori,舍去 p(a_{t+1}|s_{t+1}) 项得到:
p \left( \mathcal { O } _ { t + 1 : T } | \mathbf { s } _ { t + 1 } \right)= \beta _ { t + 1 } \left( \mathbf { s } _ { t+1 } \right)
整理得到:
\beta _ { t } \left( \mathbf { s } _ { t } , \mathbf { a } _ { t } \right) = p \left( \mathcal { O } _ { t } | \mathbf { s } _ { t } , \mathbf { a } _ { t } \right) E _ { \mathbf { s } _ { t + 1 } \sim p \left( \mathbf { s } _ { t + 1 } | \mathbf { s } _ { t } , \mathbf { a } _ { t } \right) } \left[ \beta _ { t + 1 } \left( \mathbf { s } _ { t + 1 } \right) \right]
这里可以看到已经很像 Q-learning 的形式了:
\begin{array} { l } { \operatorname { let } V _ { t } \left( \mathbf { s } _ { t } \right) = \log \beta _ { t } \left( \mathbf { s } _ { t } \right) } \\ { \operatorname { let } Q _ { t } \left( \mathbf { s } _ { t } , \mathbf { a } _ { t } \right) = \log \beta _ { t } \left( \mathbf { s } _ { t } , \mathbf { a } _ { t } \right) } \end{array}
Q _ { t } \left( \mathbf { s } _ { t } , \mathbf { a } _ { t } \right) = r \left( \mathbf { s } _ { t } , \mathbf { a } _ { t } \right) + E \left[ V _ { t + 1 } \left( \mathbf { s } _ { t + 1 } \right) \right]
再回过来看,我们忽略了
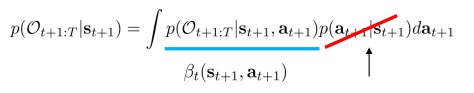
\operatorname { let } \tilde { Q } \left( \mathbf { s } _ { t } , \mathbf { a } _ { t } \right) = r \left( \mathbf { s } _ { t } , \mathbf { a } _ { t } \right) + \log p \left( \mathbf { a } _ { t } | \mathbf { s } _ { t } \right) + E \left[ V \left( \mathbf { s } _ { t + 1 } \right) \right]
V \left( \mathbf { s } _ { t } \right) = \log \int \exp \left( \tilde { Q } \left( \mathbf { s } _ { t } , \mathbf { a } _ { t } \right) \right) \mathbf { a } _ { t } \quad \Leftrightarrow \quad \quad V \left( \mathbf { s } _ { t } \right) = \log \int \exp \left( Q \left( \mathbf { s } _ { t } , \mathbf { a } _ { t } \right) + \log p \left( \mathbf { a } _ { t } | \mathbf { s } _ { t } \right) \right) \mathbf { a } _ { t }
这里认为"can always fold the action prior into the reward! uniform action prior can be assumed without loss of generality"
Policy computation
现在我们知道了对于每个状态的估值,以及 Q value,如何基于此求取我们的策略呢?
\begin{aligned} p \left( \mathbf { a } _ { t } | \mathbf { s } _ { t } , \mathcal { O } _ { 1 : T } \right) & = \pi \left( \mathbf { a } _ { t } | \mathbf { s } _ { t } \right) \\ & = p \left( \mathbf { a } _ { t } | \mathbf { s } _ { t } , \mathcal { O } _ { t : T } \right) \\ & = \frac { p \left( \mathbf { a } _ { t } , \mathbf { s } _ { t } | \mathcal { O } _ { t : T } \right) } { p \left( \mathbf { s } _ { t } | \mathcal { O } _ { t : T } \right) } \\ & = \frac { p \left( \mathcal { O } _ { t : T } | \mathbf { a } _ { t } , \mathbf { s } _ { t } \right) p \left( \mathbf { a } _ { t } , \mathbf { s } _ { t } \right) / p \left( \mathcal{O}_{ t : T} \right) } { p \left( \mathcal { O } _ { t : T } | \mathbf { s } _ { t } \right) p \left( \mathbf { s } _ { t } \right) / p \left( \mathcal{O}_{ t : T} \right) } \\ & = \frac { p \left( \mathcal { O } _ { t : T } | \mathbf { a } _ { t } , \mathbf { s } _ { t } \right) } { p \left( \mathcal { O } _ { t : T } | \mathbf { s } _ { t } \right) } \frac { p \left( \mathbf { a } _ { t } , \mathbf { s } _ { t } \right) } { p \left( \mathbf { s } _ { t } \right) } = \frac { \beta _ { t } \left( \mathbf { s } _ { t } , \mathbf { a } _ { t } \right) } { \beta _ { t } \left( \mathbf { s } _ { t } \right) } p \left( \mathbf{a}_t | \mathbf{s}_t \right) \end{aligned}
再次舍去 $ p \left( \mathbf{a}_t | \mathbf{s}_t \right)$ 得到:
\pi \left( \mathbf { a } _ { t } | \mathbf { s } _ { t } \right) = \frac { \beta _ { t } \left( \mathbf { s } _ { t } , \mathbf { a } _ { t } \right) } { \beta _ { t } \left( \mathbf { s } _ { t } \right) }
代入
\begin{array} { l } { V _ { t } \left( \mathbf { s } _ { t } \right) = \log \beta _ { t } \left( \mathbf { s } _ { t } \right) } \\ { Q _ { t } \left( \mathbf { s } _ { t } , \mathbf { a } _ { t } \right) = \log \beta _ { t } \left( \mathbf { s } _ { t } , \mathbf { a } _ { t } \right) } \end{array}
\pi \left( \mathbf { a } _ { t } | \mathbf { s } _ { t } \right) = \exp \left( Q _ { t } \left( \mathbf { s } _ { t } , \mathbf { a } _ { t } \right) - V _ { t } \left( \mathbf { s } _ { t } \right) \right) = \exp \left( A _ { t } \left( \mathbf { s } _ { t } , \mathbf { a } _ { t } \right) \right)
Forward messages
现在我们希望知道每一时刻的 s 是怎样的,即如果我每一步都是想要最优的,那么我 t 时刻会在哪里:
\begin{aligned} \alpha _ { t } \left( \mathbf { s } _ { t } \right) & = p \left( \mathbf { s } _ { t } | \mathcal { O } _ { 1 : t - 1 } \right) \\ & = \int p \left( \mathbf { s } _ { t } | \mathbf { s } _ { t - 1 } , \mathbf { a } _ { t - 1 } \right) p \left( \mathbf { a } _ { t - 1 } | \mathbf { s } _ { t - 1 } , \mathcal { O } _ { t - 1 } \right) p \left( \mathbf { s } _ { t - 1 } | \mathcal { O } _ { 1 : t - 2 } \right) d \mathbf { s } _ { t - 1 } d \mathbf { a } _ { t - 1 } \end{aligned}
p \left( \mathbf { a } _ { t - 1 } | \mathbf { s } _ { t - 1 } , \mathcal { O } _ { t - 1 } \right) = \frac { p \left( \mathcal { O } _ { t - 1 } | \mathbf { s } _ { t - 1 } , \mathbf { a } _ { t - 1 } \right) p \left( \mathbf { a } _ { t - 1 } | \mathbf { s } _ { t - 1 } \right) } { p \left( \mathcal { O } _ { t - 1 } | \mathbf { s } _ { t - 1 } \right) }
p \left( \mathbf { s } _ { t } | \mathcal { O } _ { 1 : T } \right) = \frac { p \left( \mathbf { s } _ { t } , \mathcal { O } _ { 1 : T } \right) } { p \left( \mathcal { O } _ { 1 : T } \right) } = \frac { p \left( \mathcal { O } _ { t : T } | \mathbf { s } _ { t } \right) p \left( \mathbf { s } _ { t } , \mathcal { O } _ { 1 : t - 1 } \right) } { p \left( \mathcal { O } _ { 1 : T } \right) } \propto \beta _ { t } \left( \mathbf { s } _ { t } \right) p \left( \mathbf { s } _ { t } | \mathcal { O } _ { 1 : t - 1 } \right) p \left( \mathcal{O}_{1:t-1} \right) \propto \beta _ { t } \left( \mathbf { s } _ { t } \right) \alpha _ { t } \left( \mathbf { s } _ { t } \right)
Forward/backward message intersection
根据 Forward message & Backward message 我们可以得到中间允许的状态:
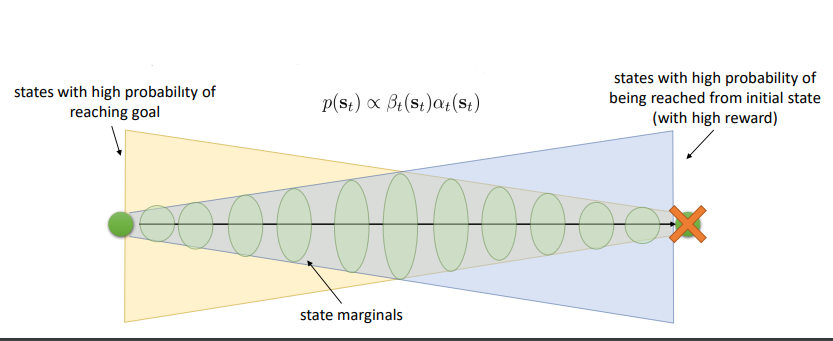
这跟我们之前说的:中间行为允许偏差,只要最后能达到目的就好是一样的。
Q-learning & Policy gradient
Q-learning

Policy gradient

这是因为加入entropy项的Policy gradient目标等价于当前策略\pi(a|s)与最优策略\frac{1}{Z}exp(Q(s,a))的KL散度
使用soft optimality的好处
- 增加exploration,避免policy gradient坍缩成确定策略
(在一般情况中训练的soft optimality)更易于被finetune成更加specific的任务 - 打破瓶颈,避免suboptimal。
更好的robustness,因为允许最优策略以及最优路径有一定的随机性。训练Policy gradient时,不同的超参数选取很容易会落到不同的suboptimal动作中。
能model人的动作(接下来的inverse RL)
Comments | NOTHING