







Abstract
本篇文章采用了 DDQN + LSTM + PPER ( Proportional Prioritized Experience Replay)。这个模型想要利用平滑移动窗中的技术指标作为输入,来输出决策。本文使用了贝叶斯优化器来寻找参数的设置。在得出模型之后,通过 White's Reality Check 来检验模型在真实的市场中是否能有较好的表现。同时选取了五个 S&P 500 (标准普尔500指数) 的股票来做分析的股票数据。最后结论是用这个方法确实能得到较好表现的模型,这个模型在验证集和测试集里都由一定的预测作用。
Whether or not stock prices are predictable?
根据 EMH (Malkiel and Fama 1970)理论,股票价格可以反应全部可以得到的信息,后来 Random Walk 理论又认为,t 和 t + 1 之间的信息是相互独立的。最终 Ballings 在 2015 年证明在一定的方差内,股票是可以预测的。 Malkiel 在 2003 提出短时间内的模式可以预测的。
因此,本篇文章主要讨论短期投资。
Reinforcement learning in trading
作者总结了从 1997 年强化学习第一次用于交易以来的方法:
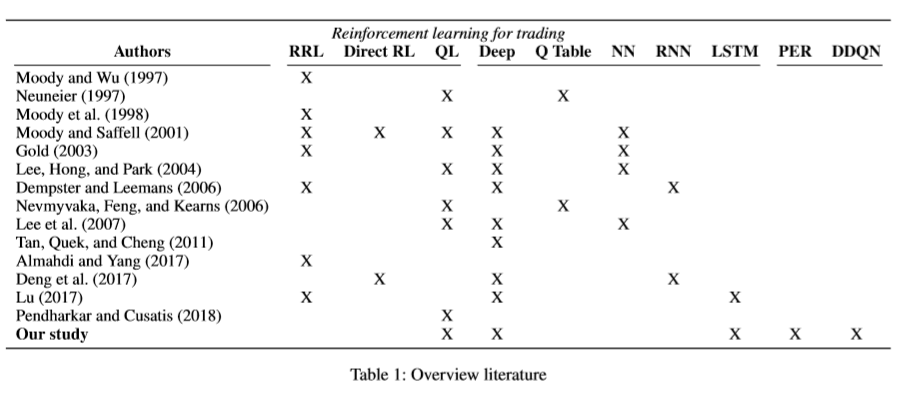
可以看出,他们是第一个把 DDQN 和 LSTM 结合在一起来做交易算法的。
Data and input features
深度学习的网络可以自动提取特征,不过作者为了给模型一个较好的 head ,于是使用了自己提取的 28 个技术指标作为网络的输入。 同时,除了实时的价格之类数据,还要告诉模型这是当天开盘第几天的数据,因此他们加入了一个变量用来表示当前状态是开盘之后的第几分钟。为了数据的一定稳定性和普适性,他们选取了 S&P 500 中的几只股票来训练模型。同时,他们把数据分为了三部分:training, validation, test
每次喂入网络的数据是一个大小为 N 的滑动窗,也就是喂入 t ~ t - N 之间的数据。
作者发现,别的文章在做的时候,没有对喂入的数据进行 Normarlization ,他们猜测是怕损失金融数据中的信息。但是这样的话,因为股票数据极其不稳定,数据一阶差分的均值、方差和数据本身的均值、方差相比,实在太小了。(比如一个股票每天波动 1% ,但是这个股票市值 400 刀,那他的一阶差分最多就是 4 ,和 400 是没法比的)。 因此作者对每次输入的窗内的数据进行了归一化,(对于全部的数据归一化是没有意义的,因为每次输入的数据只占全部数据很小很小的一部分,而输入部分的数据的波动相比全部数据而言是很小的),要注意的是,之前提到的关于开盘时间的变量不能归一化,要不然就没意义了…… 另外关于窗口大小的影响直觉上会有很大影响,但是这里受限于各种限制,不做进一步讨论。
Q Learning
作者的 base model 使用的是 2013 版的 DQN,自己搭建了交易环境,不过加入了适当调整(加入经验池优先级,DDQN)
Environment
首先肯定不能用真盘当环境……但是模拟环境会有一些问题,比如无法模拟 bid-ask 等等,这里作者设定了环境的基准准则:
- agent 的动作不会影响市场
- agent 在交易日的每分钟都可以交易
- agent 只能对一只股票做三种操作:持有,卖入,卖空
- 交易每次都要最大化股票的持有数量
这里可能有人会质疑过于简化的环境会不会对作者的结果造成较好的影响。作者认为是不会的。因为信息的缺乏反而会让 model 产生劣势,比如 model 无法知道由 Mcinish & Wood 写的 NYSE bid/ask
总体来说,作者的环境定义为:
S_t = (C_t, H_t, W_t)
其中 W 为当前滑动窗内股票的信息, C 为持有现金状况,H 为持有股票状况。
根据 S_t,agent 可选的操作有:卖空,(全部)买入,持有。
举例来说,如果某一时刻 agent 正处于持有信号,之后做出买入的动作选择,它就会买入最大允许买入的金额,剩下的现金保留。如果下一时刻还是买入信号,那么就有两种可能:1.股票跌倒足够用现金再买一次,2.不做任何操作。(因为股票有最少买入数量,比如说100股) 每个时刻,agent 的 reward 为没有经过放缩的股票持有策略的价值差(作者认为这是最具有度量性的,但是没有给出任何对比或者参考)。终止信号为:1. dataset 用完了,或者整个股票组合的价值低于了一股的价格。这时候 agent 就会重启。同时加入了 Epsilon-Greedy policy策略,不同于一般 $\epsilon{min}$ 逐渐趋于 0 ,作者的 $\epsilon{min}$ 是从 1 逐渐趋于 0.1,用来环节过拟合。
Q-function
整个网络大概的架构为,包含 35 个 cells 的 LSTM,之后是 dense layer (16 hidden nodes) 用于把 LSTM 的输出和当前的策略(买、卖、持)进行结合,之后进入输出层。LSTM 和 dense 层都含有 Dropout。通常的 DQN 中用于选择下一步动作的 Q 和选择动作之后得到的新的 Q 是同一个网络输出的,这样如果下一步的 Q 被高估了一次的话就会导致整个之前的 Q 不断被高估,造成过度乐观。因此作者采用 DDQN,用来选择 action 的 Q 和下一步的估值 Q 由两个网络输出。
即:
L(\theta) = (Q_{Target} - Q (s_t, a_t; \theta) )^2
Q_{Target} = r + \gamma Q(s_{t+1}, max_{a_{t+1}} Q(s_{t+1}, a_{t+1}; \theta); \theta_i )
Prioritized Experience Replay
作者遇到的一个问题是,在训练时 Loss 会有很多的尖峰,即使训练到 Loss 较小的时候,这些尖峰还是存在。作者分析了这些尖峰,发现都是在交易日刚开盘的时候。作者认为,以 Coca Cola 为例,开盘的数据只有 252 天(个)的,而总共的数据有 91997 个,换句话说,刚开盘的数据从经验池里提取并学习的概率实在太小了,所以模型不能很好的识别这个模式。传统的方法中,所有的训练数据都被放在了经验池中,但是作者想增加有价值的数据被提取的概率。什么是有价值的数据呢?就是那些估值和实际差别很大的数据,例如刚开盘的数据。因此他们给经验池里的数据都加上了优先级,
具体的算法他们参考了 Mnih et al (2015)

Empirical Approach
- 因为窗口被归一化了,所以 training, validation, test 三个集颠倒也无所谓。
- 因为 Adam 可以根据自动调整不同参数的学习率,对于稀疏或者噪音数据有较好的梯度,因此采用 Adam 优化器。
- 如果在验证集上 6 个连续 epochs 都没有 Sharpe radtio 的改进,就放弃这次训练。
- 由于模型超参数过多,普通的 grid search 无法找到最优参数,所以采用贝叶斯优化器寻找参数。
Results
Validation results
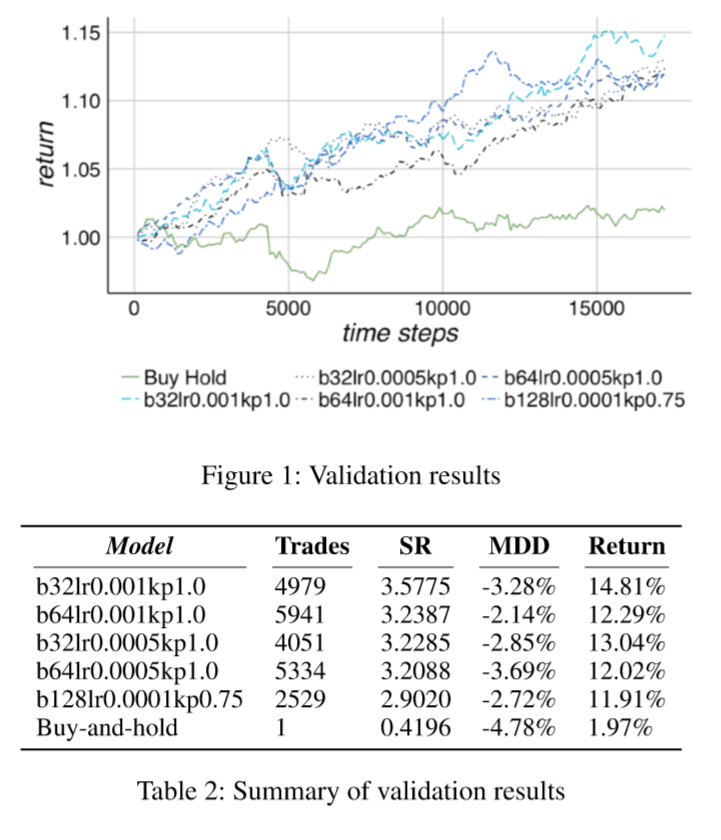
可以看到 model 产生的最优策略比 Buy-and-hold 高了 12.84%,同时 model 的最大损失为 3.28%.
Test Results
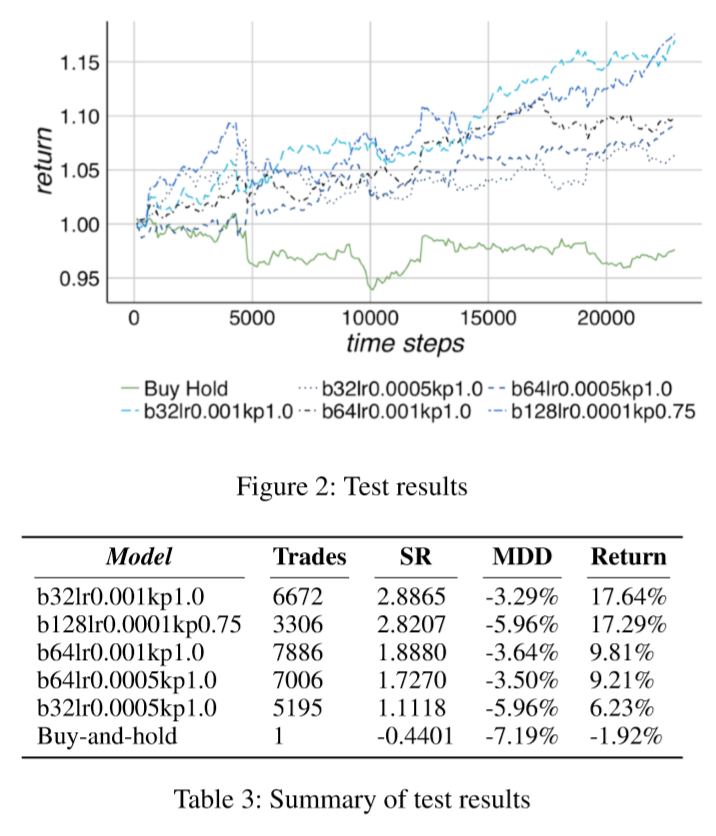
可以看到 model 在 test set 下也有不错的表现,同时最高收益率的 model 的参数和在 Validation 中的一样,其余参数的表现也基本相同。
当我们把交易放大之后:

发现:基本所有的 action 都是买入和卖空,基本没有持有,而且看起来在 13300 之后 model 开始有较高的收益。
White's Reality Check
我们希望用 Whire's Reality Check 来检验我们的结果,结果如表:
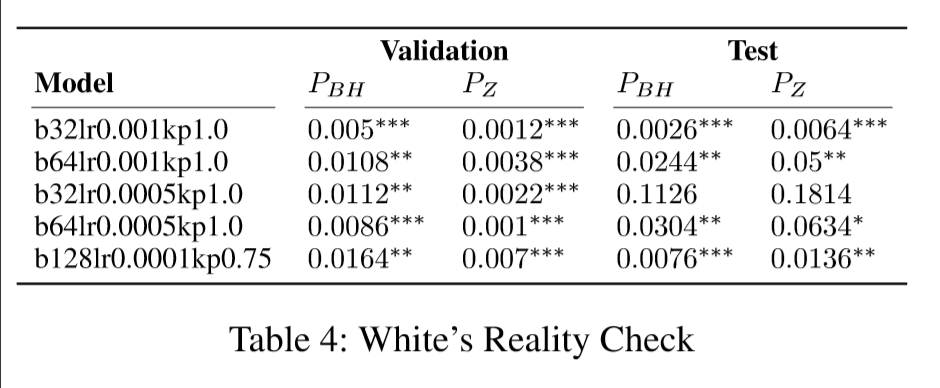
其中并不是所有参数都比 Buy & Hold 有提升, 其中四个参数有提升,三个提升超过了 5%。
Cross-validation
做了交叉验证,通过。
Overview results other stocks
只用 Coca Cola 的数据并不能说明问题,所以用了其余四支股票来做。
选取它们最好参数的模型,结果如表:
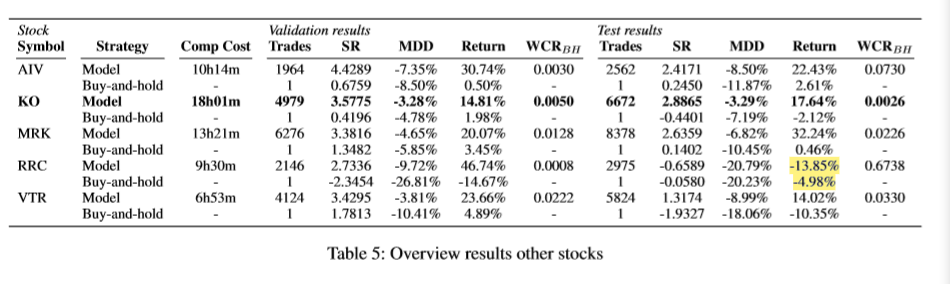
发现除了 RRC 都有较好的表现。
他们说是因为选取了一个低 Sharpe ratio 的 model 导致的。(这里没太懂)
实验环境是: 16 core 2.6 GHz computational platform with 384 Gb RAM
t-SNE
t-SNE 是继 PCA 之后的一种降维方法。
作者把 35 维的 LSTM 层数据输入,然后得到两维的图片,每个点的位置是 35 TO 2 得到的,颜色是当前状态采取的 action.
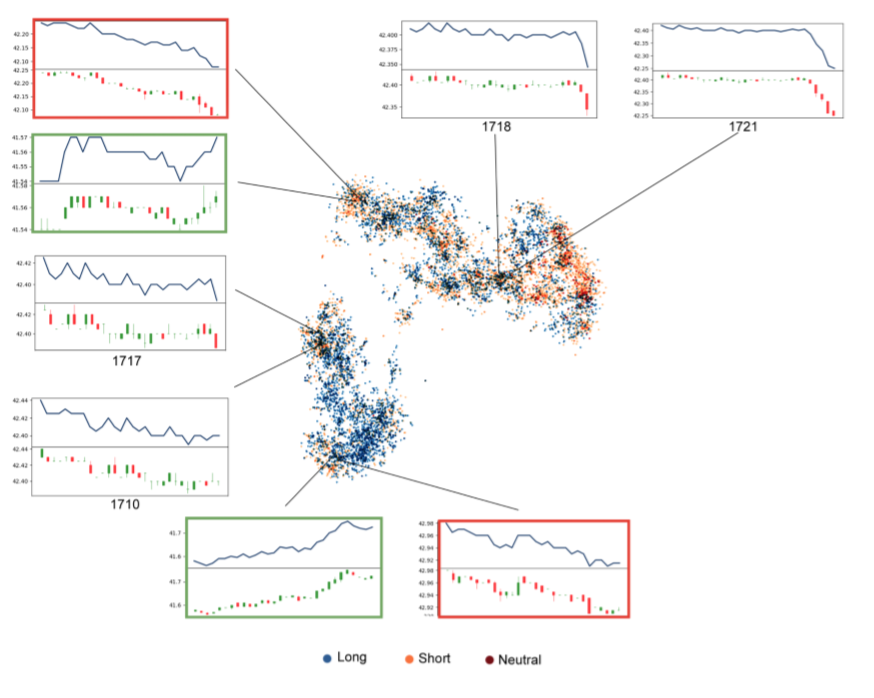
可以看到在相近位置,比如左上右下两个用红绿框圈住的地方,他们的 state 是接近的,但是 model 根据 window 最后几分钟的数据做出了不同的判断。说明 model 不仅根据过往状态做决断,同时学到了对未来状态的预测。
同时 1710 和 1717 只有 2/3 是重叠的,但是 model 也学到了他们是同一个跌势的一部分。1717 和 1718 基本全部重叠的,但是 model 识别出了最后一分钟的差别,因此认为它们是完全不同的状态。
Conclusions
这篇文章里,作者使用了 DQN 来训练 model 识别和探索短期交易模式。为了搜索超参数,对 Sharpe ratio 使用了贝叶斯优化器。之后通过交叉检验和 White's Reality Check测试 model 是优于 Buy & Hold 的。
因此我们认为,DQN 确实是能识别短期交易模式的,3/5 的股票相对于 Buy & Hold 有较大的提升。
Comments | NOTHING