







神 TM 理科课要 5000 字论文。
Background
A brif intro to saliency image

Saliency map, 说白了就是视觉显著性图像区域,人眼看到第一感兴趣的地方,用途有:自适应图像压缩和编码,图像边缘或区域加强,目标分割或提取等。
一般认为,良好的显著性检测模型应至少满足以下三个标准:
- 良好的检测:丢失实际显著区域的可能性以及将背景错误地标记为显著区域应该是低的;
- 分辨率:显著图应该具有高分辨率或全分辨率以准确定位突出物体并保留原始图像信息;
- 计算效率:作为其他复杂过程的前端,这些模型应该快速检测显著区域。
Saliency models' category
自从1998年Itti提出显著性模型以来,显著性模型主要分为三个阶段:
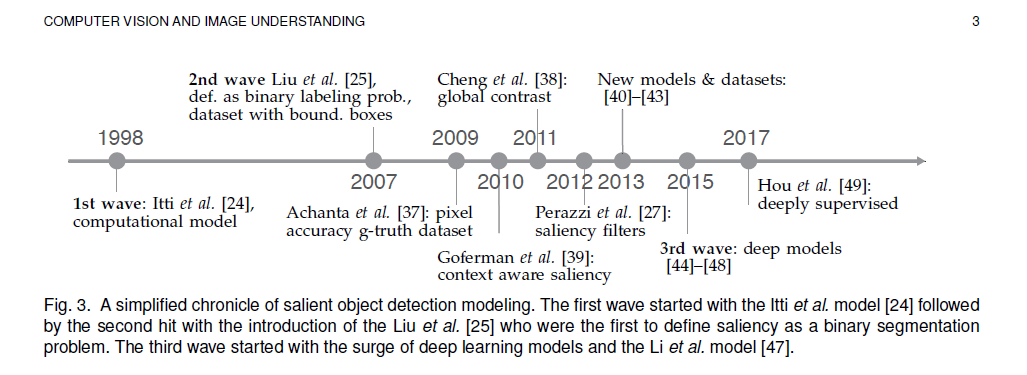
- 基于认知的模型:Itti 等人提出的最早、经典的的显著模型。掀起了跨认知心理学、神经科学和计算机视觉等多个学科的第一波热潮。
- 基于二元分割的模型:第二波热潮由刘和 Achanta 等人掀起,他们将显著性检测定义为二元分割问题,自此出现了大量的显著性检测模型。
- 基于深度学习的模型:最近出现了第三波热潮,卷积神经网络(CNN),特别是引入完全卷积神经网络。与基于对比线索的大多数经典方法不同,基于CNN的方法消除了对手工特征的需求减轻了对中心偏见知识的依赖,因此被许多科研人员所采用。基于CNN的模型通常包含数十万个可调参数和具有可变接受字段大小的神经元。神经元具有较大的接受范围提供全局信息,可以帮助更好地识别图像中最显著的区域。CNN所能实现前所未有的性能使其逐渐成为显著性物体检测的主流方向。
本文分别选取二元分割和深度学习中准确率最高的模型:DRFI 和 RAS 为基础进行实验。
A brif intro to models
DRFI
Salient Object Detection: A Discriminative Regional Feature Integration Approach 是 Huaizu Jiang, Jingdong Wang 等人 2013 年提出的模型,在2016年深度学习用于显著性检测以前,一直保持着显著性检测准确率的最高纪录。
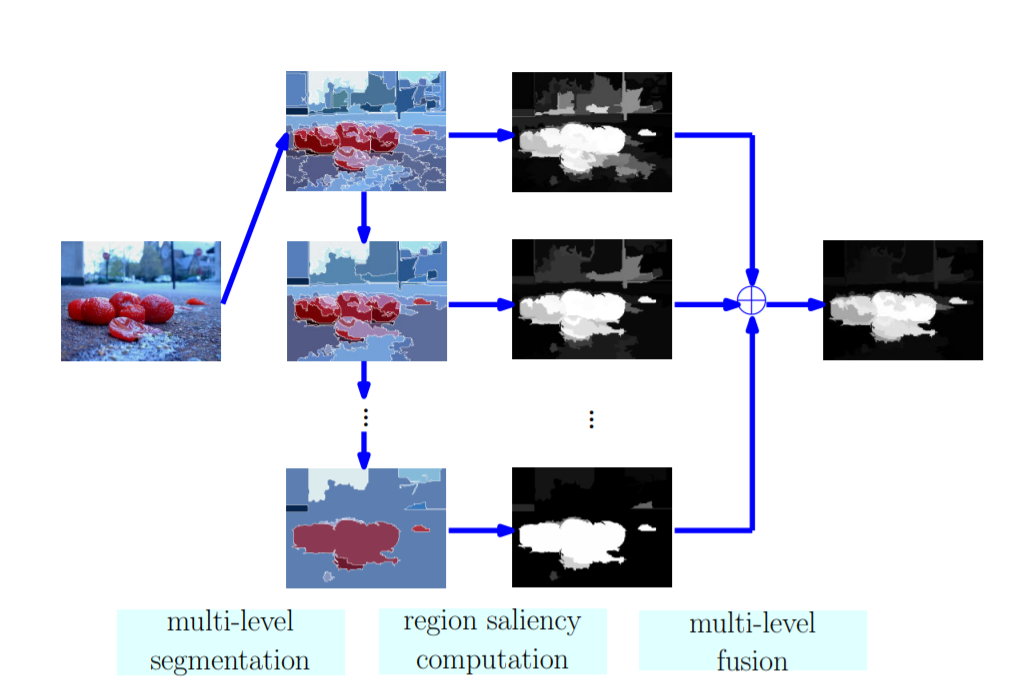
DRFI 将显著性图计算作为一个回归问题。先通过最小边权的图论方法生成过分割的图像,再通过一个 Random Forest 判断相邻区域在最后的显著性图像上为同一趋于的概率,根据这个概率,选取不同阈值,将趋于进行合并,最终得到分割等级不同的分割图像。再通过另一个 Random Forest 判断每张分割图像中的每个趋于为显著性区域的概率。最后再通过一个线性函数,把每个像素点在不同分割图像上的显著性概率进行线性叠加,得到最后的显著性图像。
我们使用 python 复现了这个模型,并进行一定的修改:减少分割图像数量以提高运行速度,将最后的线性模型替换为多层感知机以根据不同概率选择不同线性系数。
最终效果比官方差一些,但是官方那个恶心的代码让人怀疑是 CS 的人写的吗。
我们选取MSRA-B作为测试集:
| 测试集 | AUC | FPS |
|---|---|---|
| MSRA-B | 0.923 | 0.5 |
效果图如:

模型和代码已经开源:
drfi_python
RAS
Reverse Attention for Salient Object Detection 是 Chen, Shuhan and Tan 等人在 ECCV2018 中提出的模型,模型在保证 AUC 的前提下,提高了 FPS。
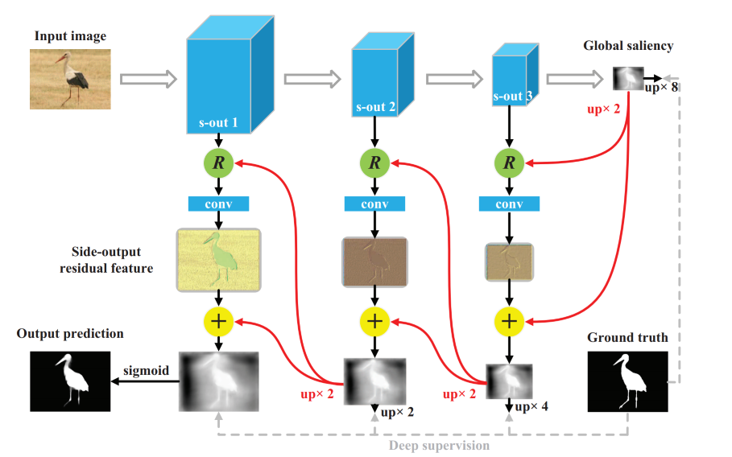
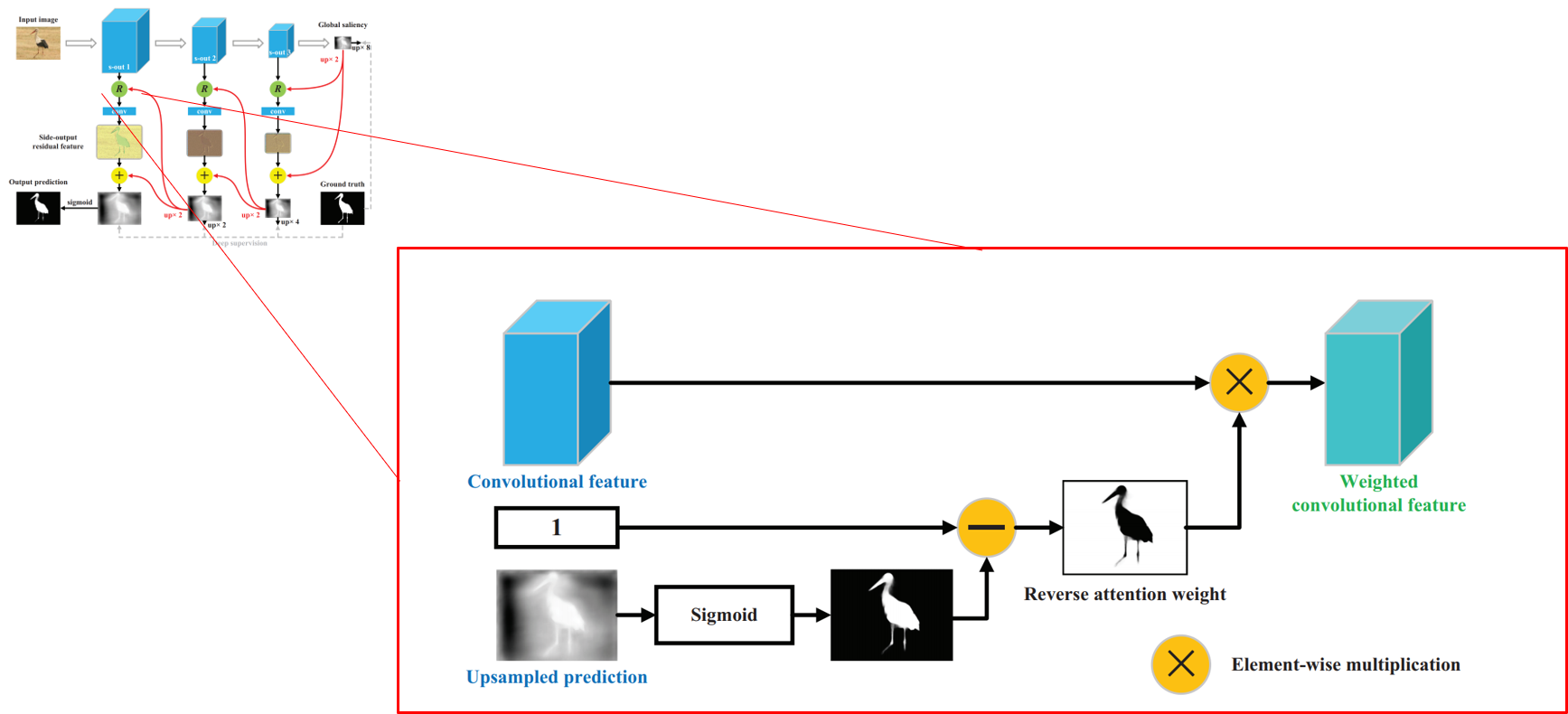
模型在传统的卷积,逆卷积的基础上,引入了和 Res Net, Dense Net 中 "高速公路" 很像的 "R" 层,使得卷积的结果和逆卷积之后的结果相结合,作者本意是将刺激信号更好的传递,但在后文中我们会看到这个结构对于盐椒噪声会有很好的抵抗性。
我们使用 pytorch 复现了这个模型,依旧选取MSRA-B作为测试集:
| 测试集 | AUC | FPS |
|---|---|---|
| MSRA-B | 0.976 | 45 |
效果图如:

模型和代码已经开源:
RAS_python
Measure Method
AUC
ROC 下面面积,不废话了。
IOU

MIOU 本为语义分割的标准度量。其计算两个集合的交集和并集之比,在语义分割的问题中,这两个集合为真实值(ground truth) 和预测值(predicted segmentation)。显著性问题可以看作只有一个目标的语义分割,也就是没有 Multi。
AUC vs IOU
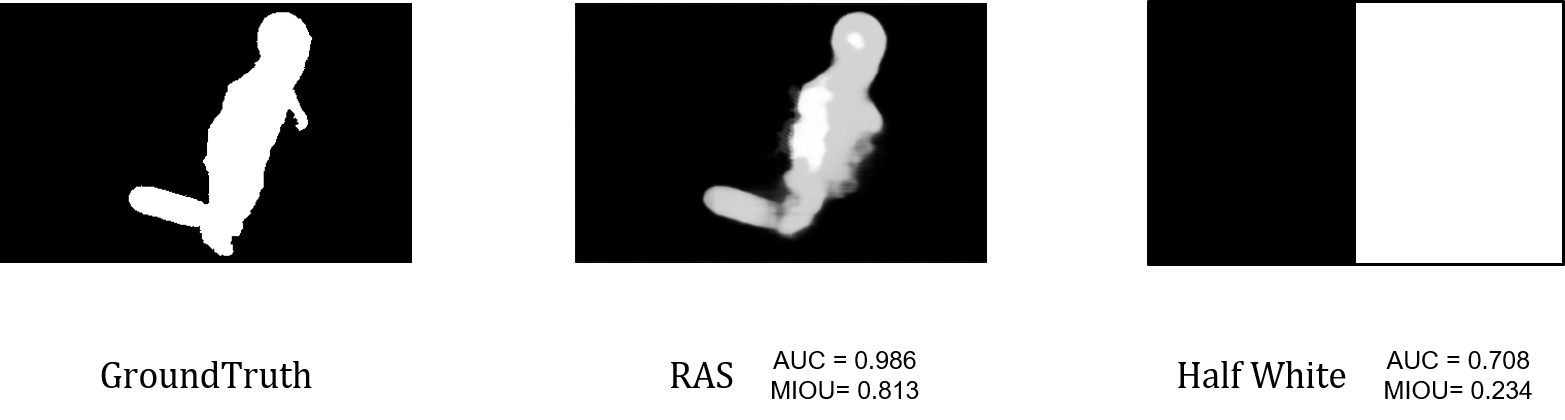
可以看到即使一张图片左白右黑,它的AUC依旧能维持在 0.7 左右较好的水准(一方面也是因为 AUC 的最低值为 0.5 ),而 IOU 则到了 0.2 左右,因此我们选取 IOU 作为我们的评价指标。
Experiment
Choose Noise
我们以盐椒噪声为例,分别选取噪声为:0.01, 0.02, 0.03, 0.04, 0.05, 0.07, 0.1, 0.15, 0.2, 0.3
噪声图如:

The noise effect to DRFI
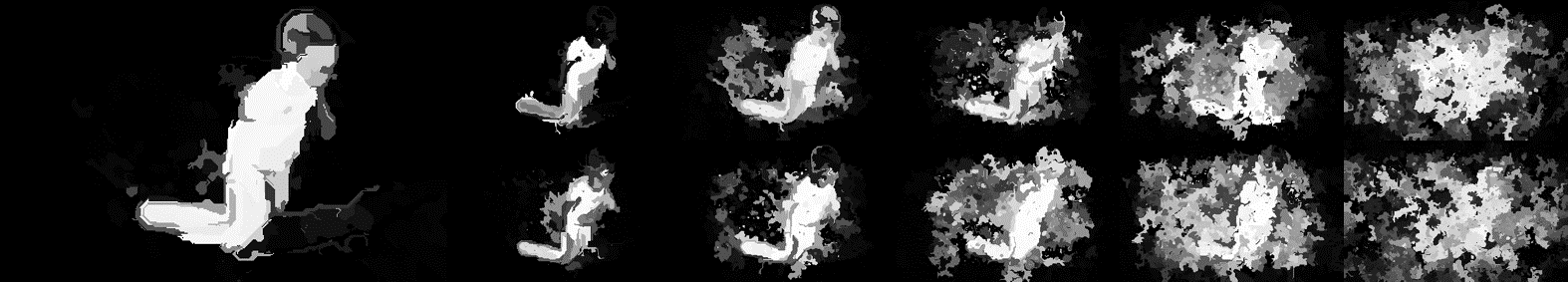
| noise | 0.00 | 0.01 | 0.02 | 0.03 | 0.04 | 0.05 | 0.07 | 0.10 | 0.15 | 0.20 | 0.30 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| AUC | 0.99 | 0.98 | 0.95 | 0.95 | 0.94 | 0.92 | 0.94 | 0.87 | 0.85 | 0.83 | 0.82 |
| IOU | 0.75 | 0.51 | 0.46 | 0.56 | 0.56 | 0.50 | 0.46 | 0.36 | 0.26 | 0.35 | 0.29 |
可以看到噪声对 DRFI 的影响较大。
为了探究噪声对 DRFI 的影响的来源,我们首先查看 RandomForest 模型中各个特征对结果影响的权重。
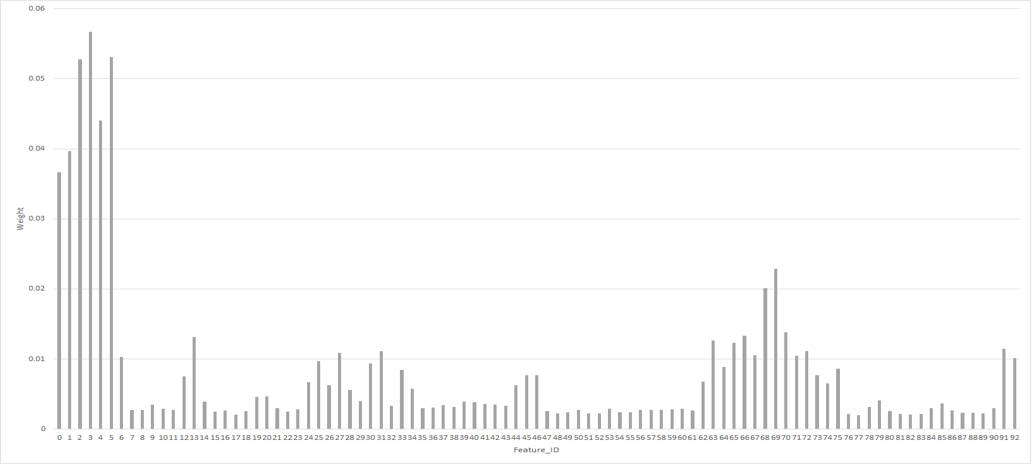
可以看到前 6 个特征权重较大,因此我们把噪声对前六个特征的影响可视化出来:

可以看到噪声确实对这六个特征有巨大影响。
这 6 个特征是区域的位置信息等特征,可以从图上看出,加入噪声后,区域过分割和合并都受到了影响,因此每个区域的相对位置特征也因此改变。
所以噪声对 DRFI 影响较为严重,其来源是因为 DRFI 的过分割受到了影响。
The noise effect to RAS

| noise | 0.00 | 0.01 | 0.02 | 0.03 | 0.04 | 0.05 | 0.07 | 0.10 | 0.15 | 0.20 | 0.30 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| AUC | 0.97 | 0.97 | 0.96 | 0.96 | 0.96 | 0.96 | 0.95 | 0.95 | 0.93 | 0.92 | 0.87 |
| IOU | 0.79 | 0.77 | 0.75 | 0.75 | 0.74 | 0.74 | 0.72 | 0.70 | 0.66 | 0.62 | 0.50 |
可以看到 RAS 对噪声有一定的鲁棒性。
为了探究噪声对 RAS 的影响,我们用 RAS 先跑一张原图,再跑一张噪声图片,分别保存中间层的图像,然后再把对应中间层的图像进行做差,最后得到的图象是:

因为是做差,所以上图中每一张都是噪声对其的影响,可以看到,每一张上都有一定的雪花噪声,可是在最后输出的图像上并没有雪花噪声,这是因为之前提到的 "R" 层起了作用。

我们简化 R 层,将 dsn-3 和 conv-3 用类似 R 层的操作分别的到 output-3,可以看到,之前在 dsn-3 和 conv-3 中的雪花噪声,在output-3 中消失了。
综上,RAS 对噪声有较好的鲁棒性,其中一部分来源于它的 "R" 层结构。
Future Work
- 以 GAN 替代 MSE loss 来增强模型泛化性。
- 尝试更多噪声,例如高斯噪声等。
Comments | NOTHING