







Abstract
作者提出了一种叫做 DF-Lens 的逆强化学习方法,用来对金融市场进行行为预测。Trader & Market 用缺少 Reward 和状态转移矩阵的 MDP 建模。作者根据 DF-Lens 对以往特征进行逐差和结合,用来学习 Trader 的行为,并做出预测。数据集基于现实中 2269480 条交易记录(Days)。
Introduction
每条交易记录包括日期,交易股票的相关信息,交易动作。我们通过学习 Trader 的交易记录,来发掘他的交易逻辑。
通过对 Trader 的策略进行估值之后可以让我们得知在现实中 Trader 会怎样进行决策,这样的好处有:
- 对于 junior traders,他们可以通过改善自己的不良行为来减少交易风险。比如一些人在面对大跌的时候会采取不理智的行为,这时候我们的行为预测就可以指出更好的策略。
- 可以用作自动化交易工具,来替代人进行交易。对于人类交易员而言,一次最多交易四五支股票就不错了,但是自动交易工具可以一次交易几千只股票。同时,它不会受情感波动的影响,所以相比人类交易员更稳定。
- 对于市场管理者,可以通过模仿所有交易者策略来预估市场对新政策的反应。
作者的数据包括来自 1165 个中国 traders 的 2269480 条数据。他们第一个实验比对了不同行为预测方法的准确性, 证实了他们 DF-Lens 方法的有效性。第二个实验分析了 DF-Lens 得到的 trader sensitiveness 的构成。他们的主要贡献为:
-
提出了一种叫做 DF-Lens 的 IRL 方法用来做金融市场行为预测,这种方法可以适用于任何金融产品。
-
提取了 trader 的高阶行为特征,用来可解释性的描述 trader 的策略。
-
在真实的金融市场数据中实验,展示了方法的可行性。
整篇 paper 构成为:
- 相关工作
- 本文基本理论
- 我们的方法及其主要部分的细节。
- 实验
- 总结
相关工作
目前行为预测主要有两种方法:Policy Classifier & IRL
Policy Classifier based Prediction
例如 SVM,但存在问题是状态太多,我们的数据只有 1000 * 30 个,状态却有 $ 31^{20}$ 个,只能 cover 掉 $ 4e^{26} $ 的状态,所以即使训练出来数据也是过拟合的。
IRL based Prediction
目前大部分 IRL 方法如 max-entropy IRL 是基于离散状态空间的,而股票市场是波动连续的,所以无法适用。而 IRL 普遍需要的 MDP/R 是需要状态转移矩阵的,但在股票市场中是无法得到的。
Concepts and Problem Definition
State Feature in Transaction
作者定义了三类 Feature:
- $s^b$: basic feature (OHLC)
- $s^t$: technical indexs (MA, MACD, KDJ, RSI, BOLL, W&R, ASI, BIAS, VR)
- $s^s$: status of the traders (fixd profit, float profit, position)
Deep Feature Lens
其实这部分就是在做 IRL Reward 函数的构建 $r(s,a) = \phi f(s,a)$,而专家轨迹就是对应 Reward 最大期望的轨迹,也就是 Max Feature Expectation Matching 而之前说缺少状态转移矩阵,就是把 Q-Learning 做成了贪心。
Temporal Feature Expectation
\begin{aligned} \tau ^ { E } ( \tilde { s } | \zeta ) & \triangleq \mathbb { E } \left[ \phi \left( s _ { t } \right) | s _ { 0 } = \tilde { s } \right] \\ & = \frac { 1 } { T } \sum _ { t = 0 , s _ { 0 } = \tilde { s } } ^ { T } \operatorname { Pr } \left( s _ { t } | s _ { t - 1 } , \ldots , s _ { 0 } \right) \phi \left( s _ { t } ; \theta _ { \phi } \right) \end{aligned}
\tau ^ { \gamma } ( \tilde { s } | \zeta ) \triangleq \sum _ { t = 0 , s _ { 0 } = \overline { s } } ^ { T } \gamma _ { \tau } ^ { t } \phi \left( s _ { t } ; \theta _ { \phi } \right)
具体来说就是对于如图数据:
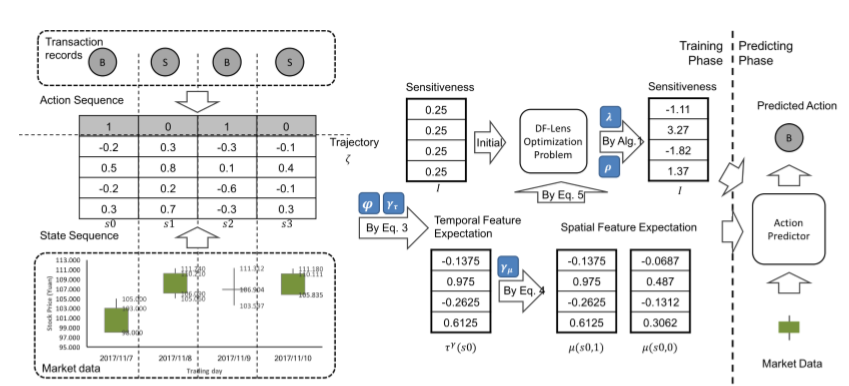
for $s_0$ as $-0.2+0.5x0.3+(0.5)^{2}x(-0.3)+(0.5)^3x(-0.1) = -0.1375 > -0.2$
说明对于这个 feature 是随时间增长的。
Spatial Feature Expectation
作者认为,专家轨迹是最大期望的,对应的其余的动作都要加一个损失系数。
\mu ( \tilde { s } , a | \tilde { a } , \zeta ) \triangleq \gamma _ { \mu } ^ { ( \mathbf { 1 } ( a \neq \tilde { a } ) ) } \tau ^ { \gamma } ( \tilde { s } )
以上面数据为例:
\mu \left( s _ { 0 } , a = 0 \right) = 0.5 * \tau \left( s _ { 0 } \right) = ( - 0.0687,0.487 , - 0.1312,0.3062 ) ^ { T }
\mu \left( \tau \left( s _ { 0 } \right) , a = 1 \right) = \tau \left( s _ { 0 } \right)
Sensitiveness Q-Learning
\begin{aligned} Q _ { \mathcal { I } _ { g } } ( \tilde { s } , a | \tilde { a } , \boldsymbol { \zeta } ) & \triangleq \mathcal { I } _ { g } ^ { T } \mu ( \tilde { s } , a | \tilde { a } , \boldsymbol { \zeta } ) \\ & = \mathcal { I } _ { g } ^ { T } \gamma _ { \mu } ^ { ( \mathbf { 1 } ( a \neq \tilde { a } ) ) } \tau ^ { \gamma } ( \tilde { s } ) \\ & = \mathcal { I } _ { g } ^ { T } \gamma _ { \mu } ^ { ( \mathbf { 1 } ( a \neq \tilde { a } ) ) } \sum _ { t = 0 , s _ { 0 } = \tilde { s } } ^ { n } \gamma _ { \tau } ^ { t } \phi \left( s _ { t } ; \theta _ { \phi } \right) \\ & = \sum _ { t = 0 , s _ { 0 } = \tilde { s } } ^ { T } \gamma _ { \tau } ^ { t } \left( \gamma _ { \mu } ^ { ( \mathbf { 1 } ( a \neq \tilde { a } ) ) } \mathcal { I } _ { g } ^ { T } \right) \phi \left( s _ { t } ; \theta _ { \phi } \right) \end{aligned}
特别的,因为测试的时候没法获取未来的数据,所以之前的 spatial feature 只用当前时间数据来做……大概只是训练的时候来做吧……
这里 Q 和 Q-Learning 里面的 Q不太相同,它更像是 IRL 中的 Reward,只是用来做 action 选择。
为了防止过拟合,加入了一个正则项:
\arg \max _ { a \in \mathcal { A } } Q _ { \mathcal { I } _ { g } } ( \tilde { s } , a | \tilde { a } , \zeta ) + \rho \mathbf { 1 } ( a \neq \tilde { a } )
最后约束条件为:
\max _ { a \in \mathbb { A } } \left( Q _ { \mathcal { I } } ( \tilde { s } , a ; \tilde { a } ) + \rho \mathbf { 1 } ( a \neq \tilde { a } ) \right) - Q _ { \mathcal { I } } ( \tilde { s } , \tilde { a } ) \leq \varepsilon
对偶优化方程为:
\begin{array} { l } { \min _ { \mathcal { I } , \varepsilon } \frac { 1 } { 2 } \| \mathcal { I } \| ^ { 2 } + \lambda \mathbb { E } [ \boldsymbol { \varepsilon } ] } \\ { s . t . \forall i , Q _ { \mathcal { I } } \left( s _ { i } , a _ { i } \right) + \varepsilon _ { i } \geq \max _ { a \in \mathbb { A } } Q _ { \mathcal { I } } \left( s _ { i } , a ; a _ { i } \right) + \rho \mathbf { 1 } \left( a \neq a _ { i } \right) } \end{array}
化成拉格朗日方程:
J ( \mathcal { I } ) = \frac { 1 } { N _ { t } } \sum _ { i = 1 \ldots N _ { t } } \mathbb { E } \left[ \max _ { a \in \mathbb { A } } Q _ { I } \left( s _ { i } , a ; a _ { i } \right) + \rho \mathbf { 1 } \left( a \neq a _ { i } \right) - Q _ { \mathcal { I } } \left( s _ { i } , a _ { i } \right) \right] + \frac { \lambda } { 2 } \| \mathcal { I } \| ^ { 2 }
因此:
\nabla \mathcal { I } ^ { t } = \mu \left( s _ { i } , \hat { a } \right) - \mu \left( s _ { i } , a _ { i } \right)
用算法表示为:

Experiments
作者用 Zhejiang Hexin Inc. 模拟比赛的数据来做的。
对比 SVM, RF 等:
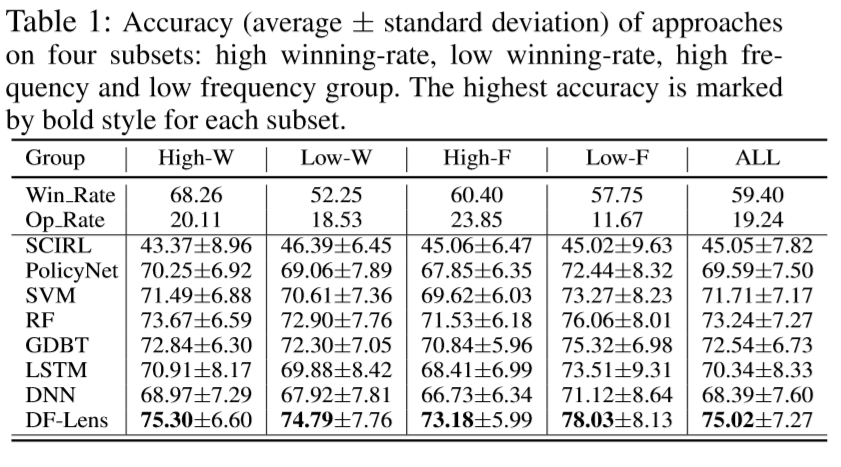
可以看到蓝点代表卖出,红点买入,灰色区域是持有,DF-Lens 明显比 RM 更贴近现实买卖行为:
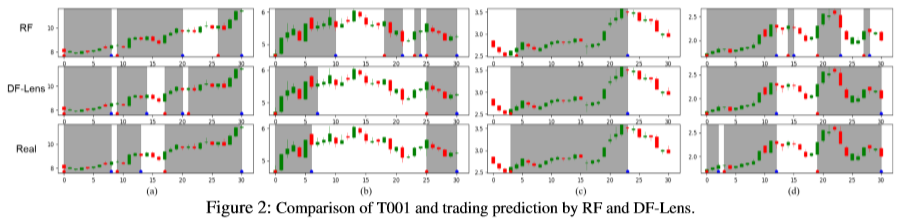
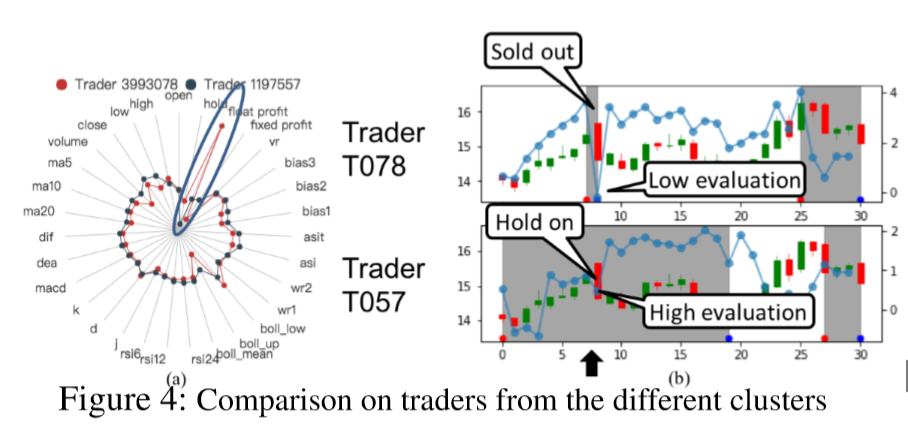
对于两个行为基本一致的 Trader,我们发现我们得到的参数分布也是基本一样的:
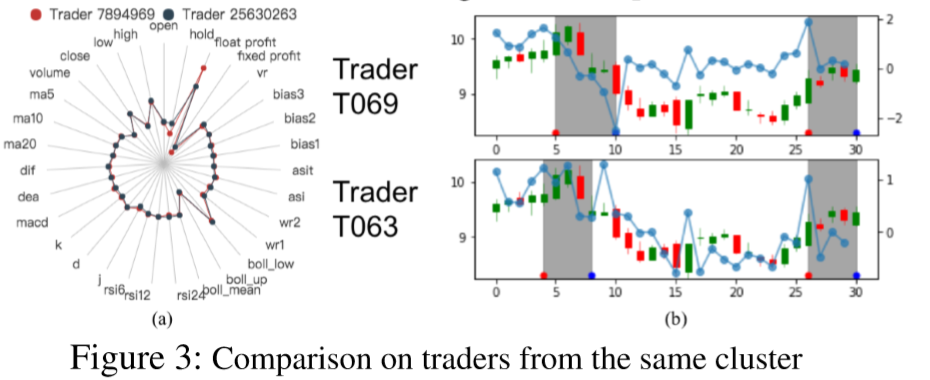
对于两个参数分布差异很大的 Trader,我们可以看到他们在第 8 天本来都持有股票,但因为 Trader078 对 float profit 更敏感,所以它在这时候选择了卖出股票,而Trader057选择继续持有:
Comments | NOTHING